Apple accélère la génération vocale par IA sans altérer la qualité
Des chercheurs d’Apple et de l’université de Tel-Aviv viennent de franchir un cap dans l’optimisation de la synthèse vocale. Leur nouvelle méthode, présentée dans une étude, permet d’accélérer de 40 % la génération de la parole à partir du texte via l’intelligence artificielle, sans pour autant sacrifier la compréhension ou la qualité audio.

L’étude se concentre sur les modèles dits « autorégressifs », une technologie similaire à celle des grands modèles de langage (LLM), mais appliquée au son. Ces systèmes prédisent habituellement le prochain fragment audio (token) en se basant sur ceux qui précèdent, un par un. Si cette approche est efficace, elle crée un goulot d’étranglement. Les chercheurs expliquent que la correspondance exacte des tokens est souvent trop restrictive : le système rejette des prédictions qui seraient pourtant auditivement correctes, simplement parce qu’elles ne correspondent pas au token précis attendu par l’algorithme, ce qui ralentit l’ensemble du processus.
Une méthode avec deux modèles pour la validation
Pour contourner ce blocage, l’équipe a développé une solution baptisée Principled Coarse-Graining (PCG). Le principe est simple : admettre que de nombreux fragments sonores différents produisent des résultats quasi identiques à l’oreille. Au lieu de traiter chaque son possible comme une entité distincte et stricte, cette méthode regroupe les tokens qui sonnent de manière similaire.
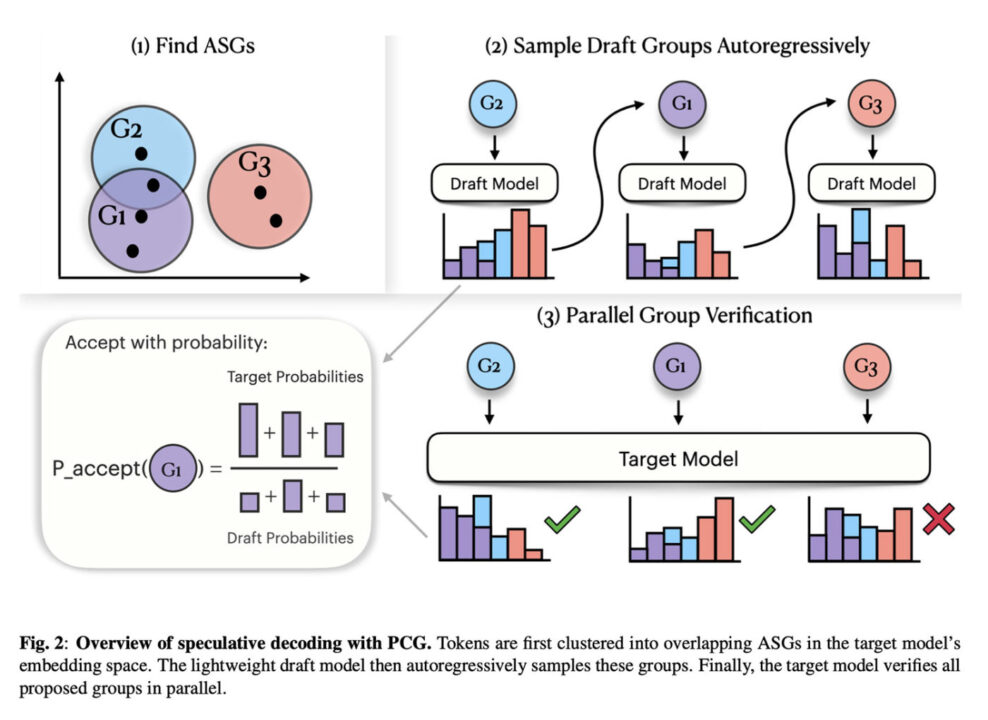
Concrètement, PCG fonctionne avec un duo de modèles. Un premier modèle, plus petit et rapide, propose des fragments audio. Un second modèle, plus grand, agit comme un juge : il vérifie si ces propositions appartiennent au bon groupe de similarité acoustique avant de les valider. Cette vérification plus souple adapte les concepts du décodage spéculatif aux modèles vocaux.
Les résultats sont concluants. La génération de la parole par IA est accélérée d’environ 40 %, une amélioration massive alors que l’application du décodage spéculatif standard n’apportait quasiment aucun gain de vitesse sur les modèles vocaux.
Une qualité préservée et une intégration facile
Cette vitesse accrue ne se fait pas au détriment de la qualité. La méthode PCG maintient un taux d’erreur sur les mots inférieur aux précédentes techniques d’accélération et préserve la similarité de la voix du locuteur. Elle atteint un score de naturel de 4,09 sur une échelle de 1 à 5. Lors d’un test de résistance extrême, les chercheurs ont remplacé 91,4 % des tokens par des alternatives du même groupe acoustique : l’audio est resté clair, avec une augmentation infime du taux d’erreur (+0,007) et une baisse négligeable de la similarité (-0,027).
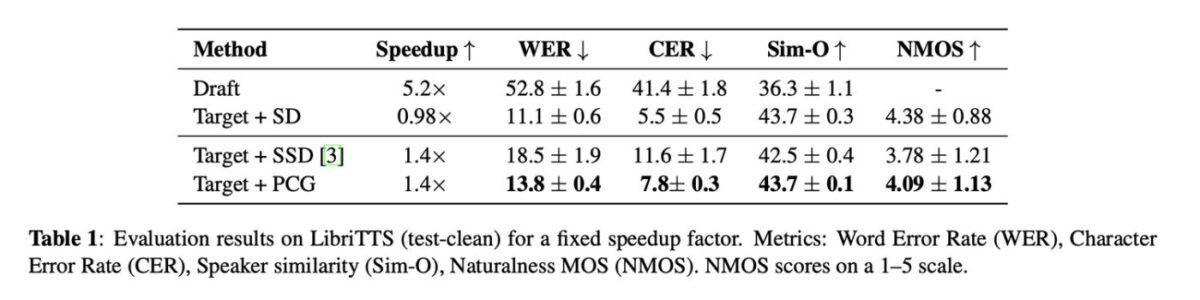
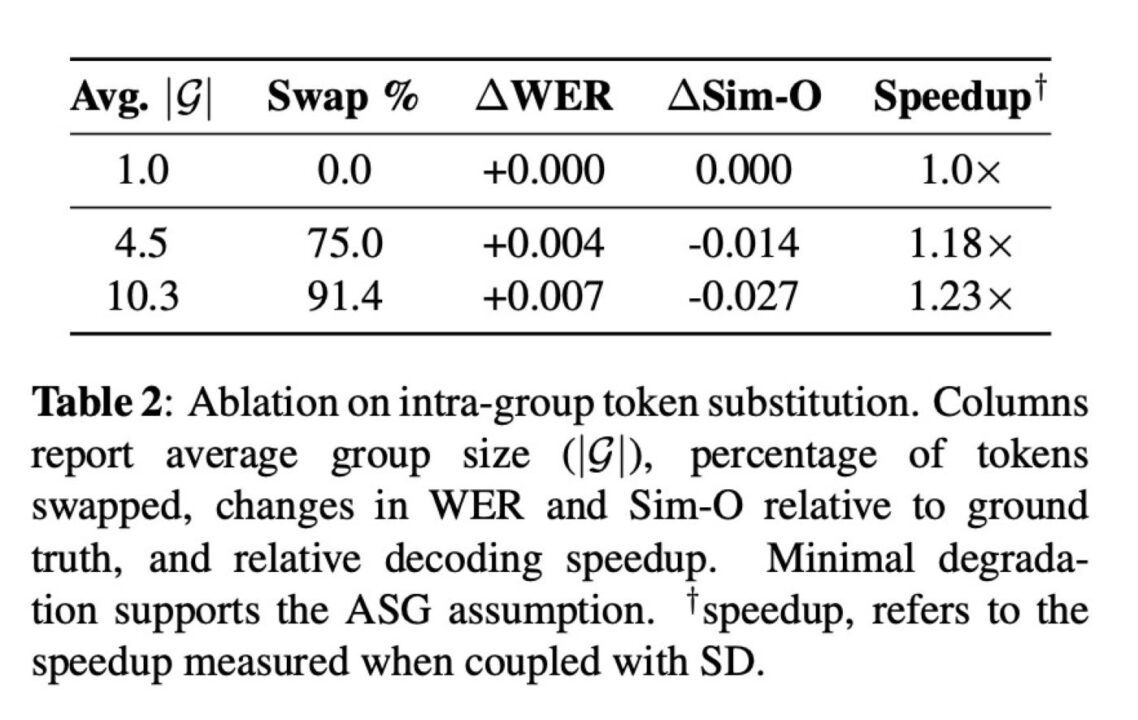
L’avantage décisif de cette technologie réside dans sa facilité de déploiement. Il s’agit d’une modification effectuée au moment du décodage, ce qui signifie qu’elle ne nécessite pas un nouvel entraînement des modèles cibles ni de changer leur architecture. Elle peut s’appliquer aux systèmes existants lors de la phase d’inférence. De plus, elle est très économe en ressources, ne réclamant que 37 Mo de mémoire supplémentaire pour stocker les groupes de similarité, ce qui la rend particulièrement pertinente pour une intégration future sur des appareils disposant de mémoire limitée.
Il ne reste plus qu’à voir maintenant comment Apple va intégrer tout ça à l’avenir sur iPhone et ses autres produits. Rien n’est dit à ce sujet pour le moment.

