RubiCap : une IA compacte d’Apple pour les images fait mieux que les grands modèles
Des chercheurs d’Apple et de l’université du Wisconsin-Madison ont mis au point RubiCap, un framework qui produit des modèles de description d’image détaillée de 2 à 7 milliards de paramètres capables de surpasser des modèles jusqu’à 72 milliards de paramètres. Le résultat le plus contre-intuitif : le modèle 3B (3 milliards de paramètres) dépasse le modèle 7B (7 milliards de paramètres) sur plusieurs benchmarks.
![]()
La description d’image détaillée consiste à identifier et décrire avec précision chaque région et élément d’une image, contrairement à une simple légende globale. Elle est centrale pour entraîner des modèles d’intelligence artificielle de vision-langage et de génération d’images, mais aussi pour améliorer la recherche visuelle et les outils d’accessibilité.
Le problème fondamental est double : produire des annotations expertes à grande échelle coûte trop cher et l’apprentissage par renforcement, qui pourrait contourner cette contrainte, n’avait jamais bien fonctionné sur des tâches comme le sous-titrage, faute de critère de vérification objectif.
RubiCap pour les descriptions d’images détaillées
RubiCap résout ce problème par une mécanique originale. Sur 50 000 images issues des données de PixMoCap et DenseFusion-4V-100K, plusieurs grands modèles de vision-langage existants (dont Gemini 2,5 Pro, GPT-5, Qwen2.5-VL-72B-Instruct, Qwen3-VL-30B-A3B-Instruct et Gemma-3-27B-IT) génèrent chacun une description. En parallèle, le modèle IA d’Apple en cours d’entraînement produit sa propre version.
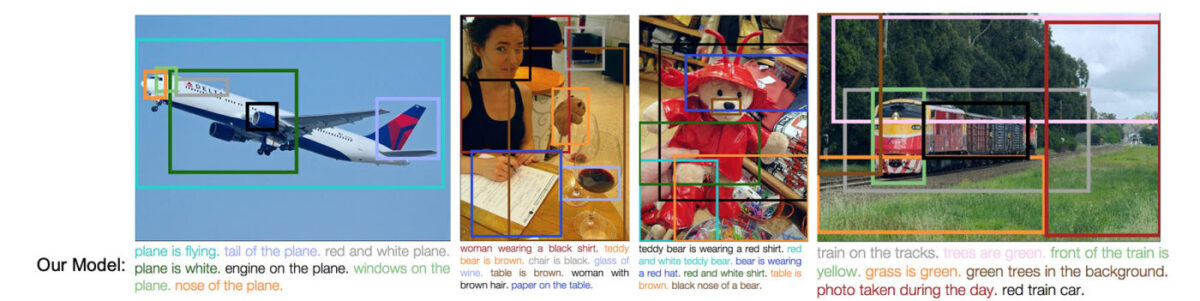
Gemini 2.5 Pro analyse alors l’ensemble des descriptions et l’image pour identifier les convergences et les lacunes, puis en extrait des critères d’évaluation structurés. C’est ensuite Qwen2.5-7B-Instruct qui note chaque description selon ces critères pour produire le signal de récompense utilisé dans l’entraînement. Le modèle reçoit ainsi un retour précis sur ce qu’il doit corriger, sans jamais dépendre d’une réponse unique prédéfinie.
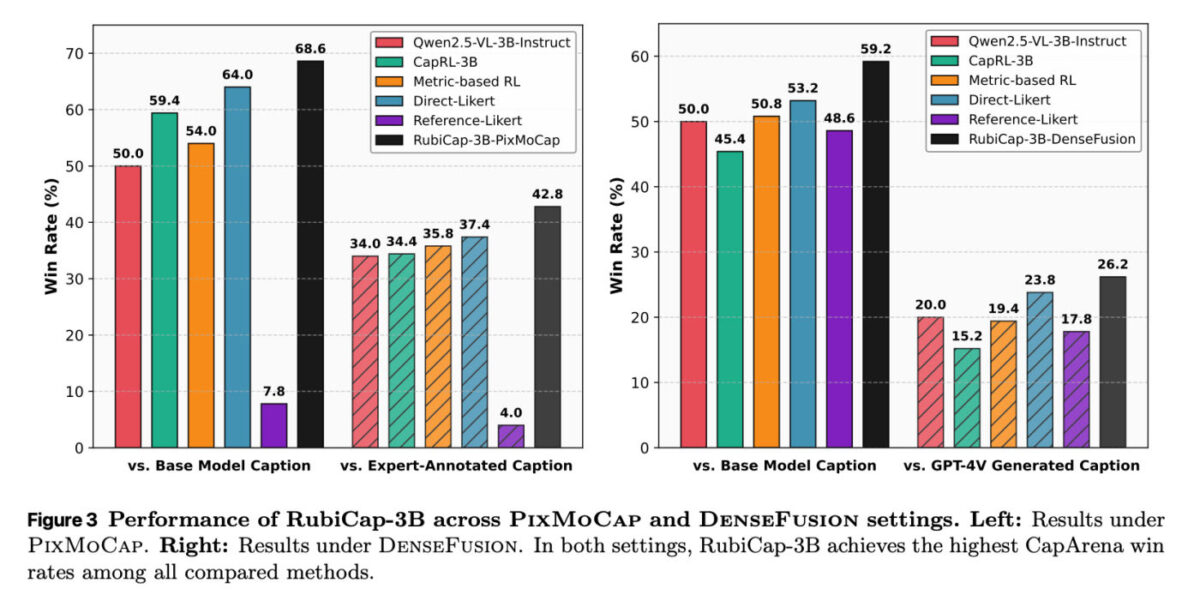
Sur le benchmark CapArena, RubiCap-7B obtient le taux de victoire le plus élevé parmi tous les modèles testés, y compris ceux à 72 et 32 milliards de paramètres, avec le taux d’hallucination le plus faible. Sur CaptionQA, le modèle 7B égale Qwen2.5-VL-32B-Instruct en efficacité lexicale, tandis que le modèle 3B dépasse le modèle 7B. Fait notable : utiliser RubiCap-3B comme générateur de descriptions produit de meilleurs modèles vision-langage pré-entraînés que ceux entraînés sur des descriptions issues de modèles propriétaires.
Comment Apple va-t-il intégrer le fonctionnement de RubiCap sur iPhone, iPad et Mac ? Rien n’est dit pour le moment, il va falloir patienter pour en savoir plus.