Ollama adopte MLX sur les Mac Apple Silicon et améliore nettement l’IA en local
L’exécution locale de modèles d’intelligence artificielle sur Mac ne cesse de progresser : Ollama, l’un des outils les plus populaires pour faire tourner des LLM en local sur macOS, Linux et Windows, s’appuie désormais sur MLX, le framework de machine learning d’Apple, pour améliorer ses performances sur les Mac Apple Silicon. L’écosystème Mac devient donc de plus en plus crédible pour l’IA embarquée.
Un moteur mieux adapté à l’architecture des puces Apple
Jusqu’ici, Ollama permettait déjà de charger et d’exécuter localement des modèles open source, mais l’expérience restait fortement contrainte par la mémoire disponible et par les limites de traitement des machines grand public. En basculant vers MLX sur Apple Silicon, l’application peut désormais mieux exploiter l’architecture à mémoire unifiée des puces maison, un atout majeur dans le domaine de l’inférence locale.
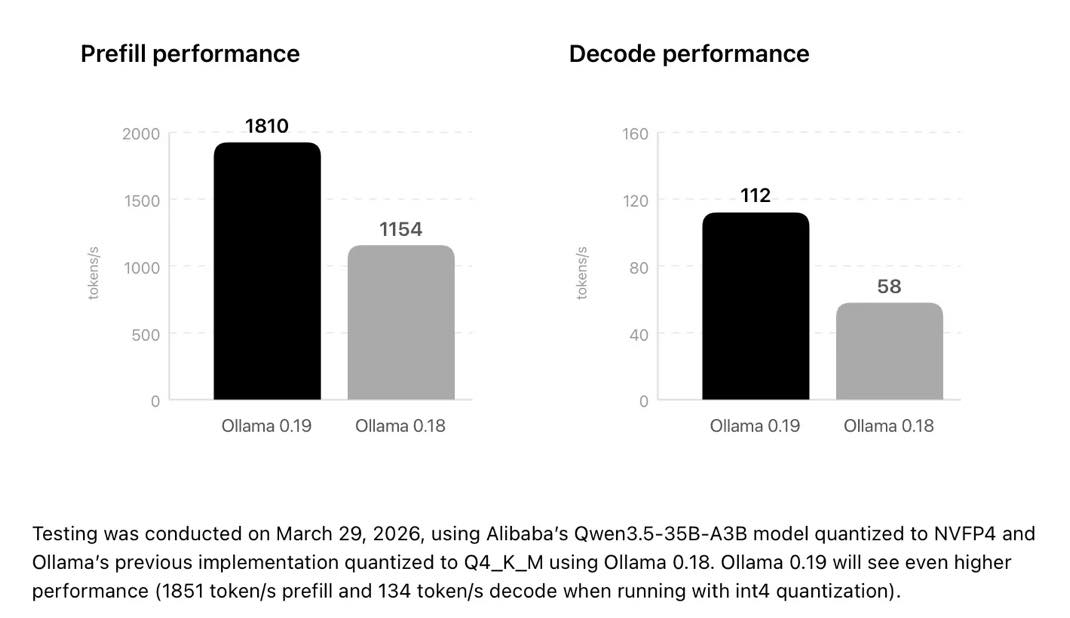
Cette intégration se traduit par un gain de vitesse annoncé sur l’ensemble des Mac Apple Silicon compatibles, avec une amélioration à la fois du temps nécessaire avant le premier token et du débit de génération. Autrement dit, les réponses arrivent plus vite et s’enchaînent de façon plus fluide, ce qui change concrètement l’expérience pour les utilisateurs de modèles locaux.
Le Mac, une machine de référence pour l’IA personnelle ?
Ce progrès intéressera particulièrement les utilisateurs qui exécutent des assistants personnels, des agents de programmation ou des modèles spécialisés directement sur leur machine. L’enjeu n’est pas seulement plus de confort mais touche aussi à la confidentialité, à l’autonomie hors ligne et à un contrôle plus fin des données manipulées.
Une promesse encore réservée aux configurations musclées
Cette avancée a toutefois une limite importante : pour profiter pleinement de cette nouvelle base technique, Ollama recommande un Mac doté de plus de 32 Go de mémoire unifiée. Cela restreint de fait l’accès à cette expérience optimisée à des machines déjà relativement haut de gamme, loin du parc installé le plus large.
Une évolution qui dépasse le seul cas d’Ollama
L’adoption de MLX par un outil aussi utilisé qu’Ollama montre qu’Apple n’avance plus seulement sur l’IA à travers ses propres fonctions système. La firme de Cupertino construit aussi discrètement un socle technique capable d’attirer les développeurs et les outils tiers vers le calcul local sur Mac. À mesure que les modèles deviennent plus efficaces et que les usages s’éloignent du « tout-cloud », ce type d’optimisation pourrait faire du Mac une plateforme de référence pour l’IA personnelle et embarquée.