Matrix3D : Apple dévoile un modèle d’IA capable de créer des scènes 3D à partir d’images 2D
L’équipe Machine Learning d’Apple, en collaboration avec des chercheurs de l’Université de Nanjing et de l’Université des Sciences et Technologies de Hong Kong, a dévoilé Matrix3D — un puissant nouveau modèle d’IA capable de reconstruire des scènes et objets en 3D à partir de seulement quelques photos en 2D. Contrairement aux technologies logicielles de photogrammétrie qui reposent sur plusieurs modèles distincts pour des tâches comme l’estimation de pose et la prédiction de profondeur, Matrix3D utilise une architecture unifiée qui simplifie considérablement le processus, et améliore à la fois l’efficacité et la précision en traitant simultanément les images, les paramètres de la caméra et les données de profondeur.
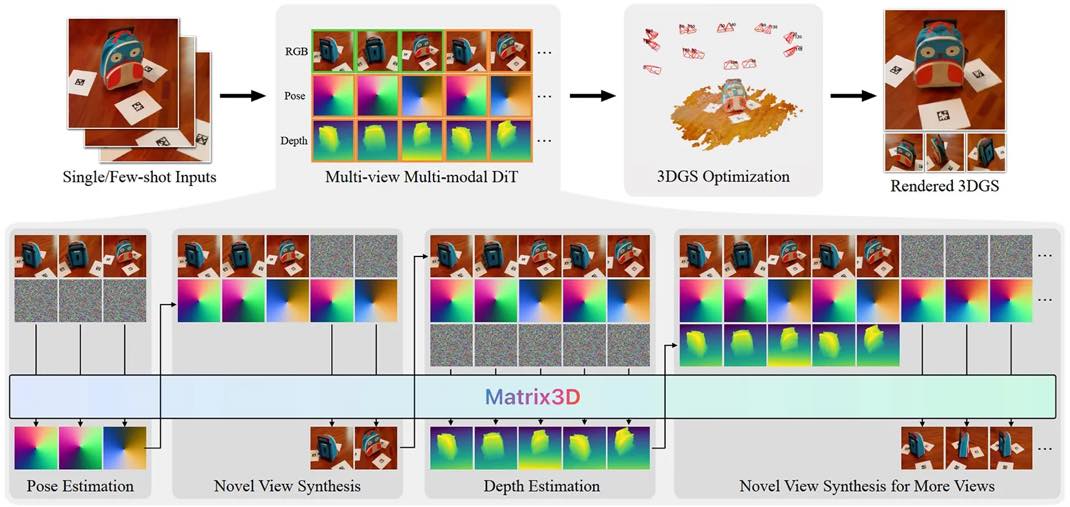
Ce qui distingue encore Matrix3D, c’est sa méthode d’entraînement innovante. Le modèle a en effet été entraîné à l’aide d’une stratégie d’ »apprentissage masqué », similaire à celle utilisée par les premiers modèles Transformers comme ChatGPT. En masquant certaines parties des données d’entrée pendant l’entraînement, Matrix3D a appris à combler les lacunes, ce qui lui permet de fonctionner efficacement même avec des jeux de données limités ou incomplets. Le résultat est un système performant capable de générer des reconstructions 3D précises à partir de seulement trois images — une avancée prometteuse pour les technologies de réalité augmentée et virtuelle, notamment avec des appareils comme l’Apple Vision Pro. A noter que le code de ce projet est en open source sur GitHub.

