LGTM : Apple dévoile un framework qui améliore le rendu 3D 4K, notamment pour le Vision Pro
Apple explore une nouvelle piste pour accélérer la création de scènes 3D détaillées sans faire exploser le coût de calcul. Avec LGTM, ses chercheurs ciblent un élément bien identifié : les méthodes rapides actuelles peinent à suivre dès que la résolution grimpe vers la 2K et la 4K.

Derrière LGTM, Apple cherche à rendre plus viable un rendu 3D riche en détails dans des usages où la vitesse compte autant que la fidélité visuelle.
Dans une étude, les chercheurs d’Apple et de l’université de Hong Kong partent d’un problème précis. Les approches de projection gaussienne 3D à propagation directe permettent de transformer une ou plusieurs images en scène 3D observable sous de nouveaux angles, mais leur coût devient rapidement trop élevé quand la définition augmente.
Ce défaut crée un écart entre la rapidité et la qualité. Les méthodes par optimisation scène par scène restent plus lentes, mais produisent en général des résultats plus stables, tandis que les approches à propagation directe vont plus vite sans bien passer à la haute résolution.
Apple change la manière de répartir le détail avec LGTM
LGTM n’est pas présenté comme un nouveau modèle autonome. Apple le décrit plutôt comme un framework qui vient renforcer des méthodes existantes en modifiant la manière dont elles représentent le détail visuel.
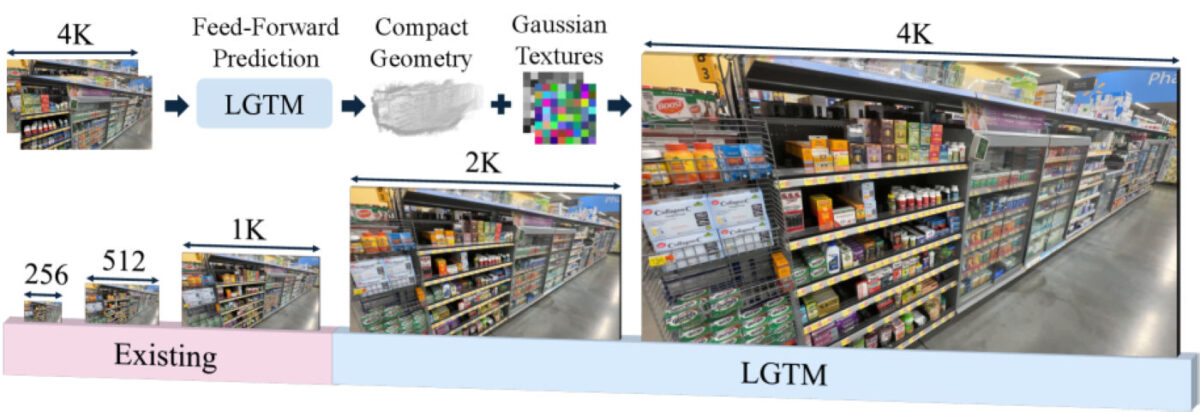
Le principe central consiste à séparer la structure d’une scène de son apparence fine. Les chercheurs expliquent que LGTM dissocie la complexité géométrique de la résolution de rendu, ce qui permet de garder une géométrie simple tout en ajoutant des textures détaillées par-dessus.
Cette architecture repose sur deux étages. D’abord, le système apprend la structure de la scène à partir d’images basse résolution, puis confronte ce résultat à un véritable contenu en haute résolution afin d’obtenir une géométrie qui reste correcte en 2K ou en 4K, sans trous ni artefacts visibles.
Ensuite, un second réseau se concentre sur l’apparence. Il prend des images haute résolution et apprend des textures fines pour chaque élément géométrique, de façon à superposer le détail visuel à une base plus légère.
Un gain de calcul qui vise aussi le Vision Pro
L’intérêt tient au rendement. LGTM permet d’améliorer des systèmes existants pour produire des scènes détaillées en 4K sans provoquer l’explosion des besoins de calcul qui rendait les anciennes méthodes de propagation directe peu praticables à haute résolution.
Cet angle devient particulièrement concret avec le Vision Pro. Le casque dispose de deux écrans totalisant environ 23 millions de pixels, soit plus de pixels par œil qu’un téléviseur 4K, ce qui rend le goulet d’étranglement du rendu encore plus sensible.

Dans ce contexte, LGTM pourrait aider à fluidifier les performances tout en affinant l’image lorsque ce type de génération 3D rapide est nécessaire. En usage réel, cela pourrait ouvrir la voie à des environnements immersifs plus détaillés ou à des expériences plus réalistes, sans laisser la demande de calcul s’emballer.
Les exemples visuels mis en avant vont dans ce sens. Ils montrent des résultats plus riches en textures et en texte, et plus proches des images de référence.
