Apple dévoile la puissance de sa puce M5 pour l’IA locale
Apple vient de publier une analyse technique qui confirme ce que beaucoup pressentaient : la nouvelle puce M5 sur Mac n’est pas une simple itération, mais une refonte pensée pour l’intelligence artificielle locale. À travers son framework open source MLX, Apple démontre que la puce M5 creuse un écart significatif avec la génération précédente.

Génération d’images par IA : une accélération notable
Le chiffre le plus impressionnant concerne la création visuelle. La puce M5 pulvérise son aînée en générant des images 3,8 fois plus vite que la puce M4. Ce bond en avant ne doit rien au hasard : il est le fruit d’une nouvelle architecture matérielle.
Apple a intégré de nouveaux accélérateurs neuronaux au niveau du GPU (partie graphique) spécifiquement dédiés aux multiplications matricielles, opérations mathématiques au cœur des algorithmes de génération d’images. Là où la M4 traitait ces tâches avec compétence, la M5 les exécute de manière bien plus efficace, rendant les flux de travail créatifs quasi instantanés.
LLM : la bande passante de la puce M5 aide
Pour les grands modèles de langage (LLM), le gain est moins important mais tout aussi crucial pour la fluidité. Les benchmarks réalisés sur des modèles comme Qwen ou GPT-OSS d’OpenAI montrent une amélioration de 19 % à 27 % lors de la génération de texte. Ici, ce n’est pas le calcul pur qui prime, mais la vitesse à laquelle les données circulent.
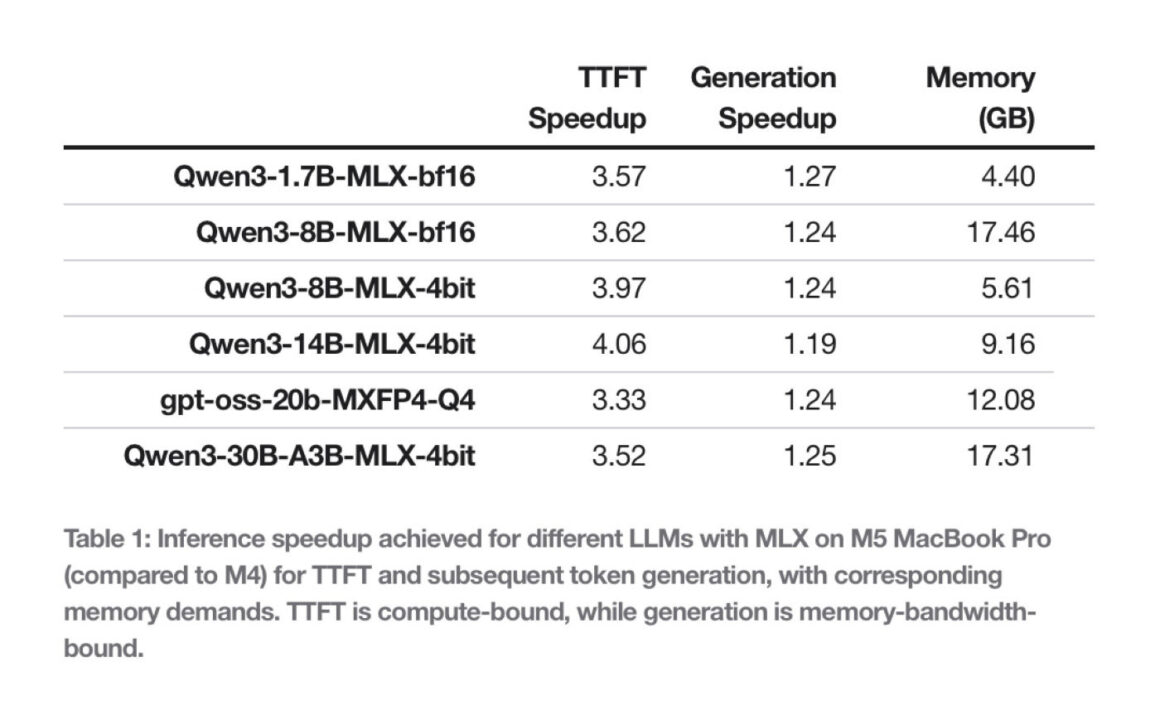
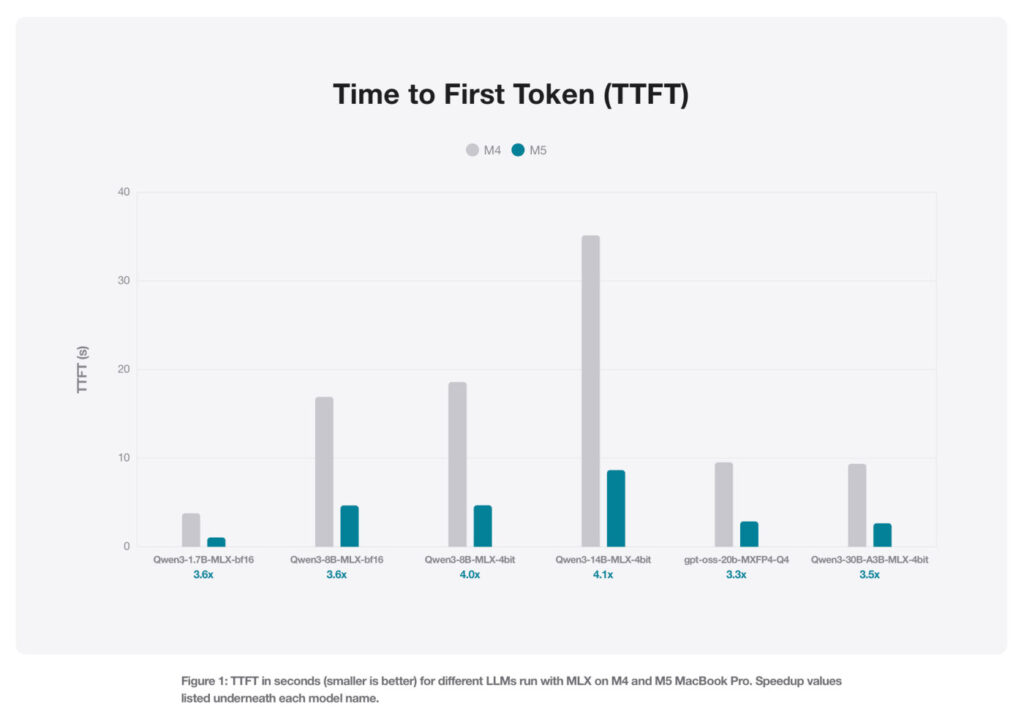
L’inférence de texte étant fortement dépendante de la mémoire, la puce M5 tire profit de sa bande passante mémoire accrue de 28 %, atteignant 153 Go/s contre 120 Go/s pour la M4. Cette mémoire plus importante permet au framework MLX d’alimenter le processeur sans goulot d’étranglement, fluidifiant les conversations avec les assistants locaux.
Au-delà de la vitesse brute, Apple insiste sur la capacité concrète de ses machines à héberger ces intelligences. Grâce à la quantification (compression des modèles d’IA) supportée nativement par MLX, un MacBook Pro doté de 24 Go de RAM peut faire tourner confortablement un modèle de 30 milliards de paramètres (30B) tout en gardant une empreinte mémoire sous les 18 Go.
Cela signifie que les développeurs peuvent exécuter des modèles complexes issus de Hugging Face directement sur leur machine, sans envoyer de données dans le cloud. Avec la puce M5, l’IA locale quitte le domaine de l’expérimentation pour devenir un outil de production viable et rapide.